
Integrating machine learning into end-user applications has become increasingly important in driving business decisions and growth. With the emergence of various tools and platforms, the deployment of machine learning models has become more efficient.

However, there are still challenges associated with developing and deploying these models.
Understanding Machine Learning Model Deployment Architecture
Machine learning model deployment architecture refers to the structure and organization of deploying ML models. There are different deployment architectures available, including:
Embedded architecture:
The embedded architecture involves integrating the machine learning model directly into the end-user application. It means that the model deployment becomes an integral part of the application’s code and functionality.
By embedding the model, the application can make real-time predictions without the need for external API calls. This architecture is beneficial for scenarios where low latency and immediate response are crucial, such as real-time image recognition in mobile applications.
Dedicated Model API architecture:
The dedicated Model API architecture deploys the machine learning model as a dedicated API endpoint. External applications or services can interact with the model by making API calls to the endpoint. This approach allows for decoupling the model from the application, making it easier to update or replace the model without impacting the application’s codebase. It provides a standardized interface for making predictions, enabling seamless integration with other systems.
Model published as data architecture:
In the model published as data architecture, the machine learning model is published as data that can be accessed and utilized by other systems. Instead of deploying the entire model, the model’s parameters or predictions are made available as data.
This architecture is useful when there is a need to share model predictions or parameters across multiple applications or when the model is too large to be deployed directly. Other systems or applications can consume this data and utilize it according to their needs.
Offline predictions architecture:
The offline predictions architecture involves generating predictions in a batch or offline manner. Instead of making real-time predictions, the model processes a batch of input data and generates predictions for all the inputs at once.
This architecture is suitable when real-time response is not required, and it is more efficient to process data in batches. It is commonly used for tasks such as large-scale data analysis or generating predictions for a large dataset.
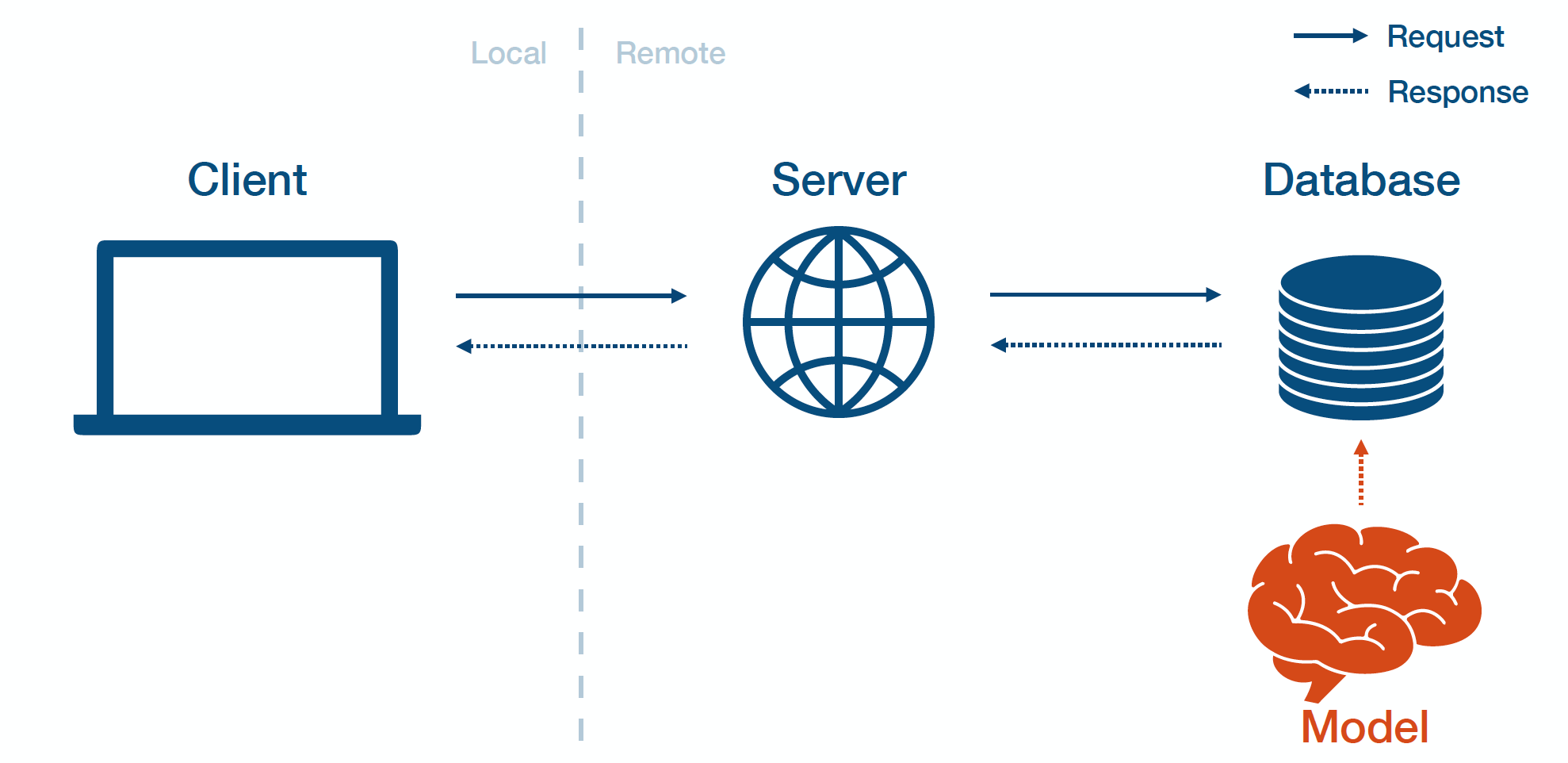
Methods of Machine Learning Model Deployment
There are several methods for deploying machine learning models, each with its own advantages and use cases:
Embedded model deployment: Embedded deployment involves integrating the machine learning model directly into the end-user application. This approach enables real-time predictions within the application itself, without relying on external API calls. It is advantageous when low latency and immediate response are crucial, such as real-time image recognition in mobile applications.
Web API model deployment: Web API deployment exposes the machine learning model as an API endpoint. This allows external applications or services to make API calls to interact with the model and obtain predictions. Web API deployment decouples the model from the application, making it easier to update or replace the model without affecting the application’s codebase. It provides a standardized interface for making predictions and enables seamless integration with other systems.
Cloud-based model deployment: Cloud-based deployment involves deploying the machine learning model on a cloud platform. This method offers scalability, accessibility, and flexibility. By leveraging cloud infrastructure, organizations can easily scale their models to handle increasing workloads. Cloud platforms also provide additional services for managing, monitoring, and securing the deployed models.
Container model deployment: Container deployment involves packaging the machine learning model into containers, such as Docker containers. This approach offers portability and ease of deployment across different environments. Containers encapsulate the model, its dependencies, and the necessary runtime environment, ensuring consistency and reproducibility. Container deployment simplifies the deployment process and supports efficient scaling and management of models.
Offline model deployment: Offline deployment focuses on precomputing inference scores in an offline environment. The model generates predictions in batches or for large datasets, and the inference scores are stored for subsequent lookup. This method is suitable for scenarios with large datasets or batch predictions, where real-time response is not required. Offline deployment is commonly used for tasks like monthly income predictions for vacation rental properties.
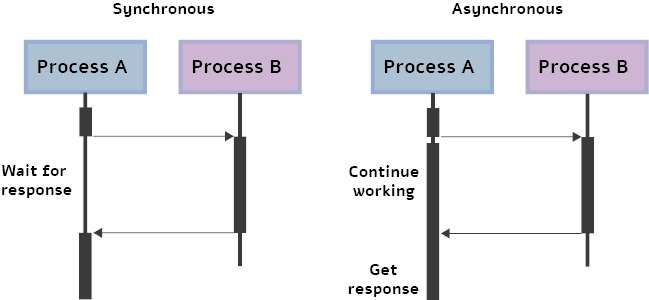
Real-time synchronous inferencing: Real-time synchronous inferencing involves making real-time predictions by using a request/response pattern. Applications or services send requests to the model serving infrastructure, which responds with predictions. This method often utilizes RESTful API calls to interact with the model and obtain real-time results. Real-time synchronous inferencing is suitable for scenarios requiring immediate predictions and quick response times.
Offline batch inferencing: Offline batch inferencing precomputes inference scores in an offline environment. The model processes a batch of input data and generates predictions for all inputs at once. The inference scores are then loaded into a key-value store for subsequent lookup. Offline batch inferencing is useful when real-time response is not needed and it is more efficient to process data in batches. It is commonly used for tasks like monthly income predictions for vacation rental properties.
Stream inferencing: Stream inferencing involves performing predictions as inputs arrive on a stream. The model continuously processes incoming data, generating predictions as the data streams in. The inference results are updated in a key-value store, allowing real-time access to the most recent predictions. Stream inferencing is well-suited for scenarios where low-latency, continuous predictions are required, such as real-time event processing or anomaly detection.
Top 9 Machine Learning Deployment Tools
To facilitate efficient machine learning deployment, there are various tools available in the market. Here are the top 9 tools:
Kubeflow: Kubeflow is a platform that provides a framework for deploying machine learning workflows on Kubernetes clusters. It offers a range of features, including model training, hyperparameter tuning, and serving. With Kubeflow, organizations can orchestrate the end-to-end machine learning pipeline, ensuring scalability, portability, and reproducibility.

Gradio: Gradio is a tool that simplifies the process of creating and deploying machine learning models as web interfaces. It offers a user-friendly UI that allows data scientists and developers to build interactive and customizable interfaces for their models without requiring extensive coding knowledge. Gradio supports a wide range of ML frameworks and makes it easy to share and deploy models as web applications.
Cortex: Cortex is a machine learning deployment platform that focuses on supporting multi-framework model serving. It provides capabilities for deploying models at scale, ensuring high availability and fault tolerance. Cortex also offers built-in model monitoring functionalities, allowing users to track model performance, detect anomalies, and analyze usage patterns.
Seldon.io: Seldon.io is an open-source framework that simplifies the deployment of machine learning models. It provides features for managing, scaling, and monitoring models in production environments. Seldon.io offers scalability and flexibility, enabling organizations to deploy models across various infrastructure options, including Kubernetes and cloud platforms.
BentoML: BentoML is a framework that streamlines the process of creating and maintaining production-grade APIs for machine learning models. It allows data scientists and developers to package their models along with the necessary dependencies and configurations into a containerized format. BentoML provides easy-to-use APIs for serving the models and supports popular ML frameworks.

SageMaker: SageMaker is a comprehensive machine-learning platform offered by AWS. It provides a wide range of tools and services for end-to-end model development, training, and deployment. SageMaker offers features such as data labeling, automated model tuning, and managed infrastructure for deploying models at scale. It integrates seamlessly with other AWS services, enabling organizations to build robust ML pipelines.
Torchserve: Torchserve is a model-serving framework specifically designed for PyTorch models. It provides a production-ready environment for deploying PyTorch models with built-in support for various model types and libraries. Torchserve offers features like multi-model serving, auto-scaling, and monitoring, making it easier to deploy and manage PyTorch models in production.
Kubernetes: Kubernetes is an open-source platform for managing containerized tasks, including machine learning model deployment. It provides a scalable and flexible infrastructure for deploying and orchestrating ML models in a distributed environment.

Kubernetes offers features like auto-scaling, load balancing, and resource management, allowing organizations to efficiently deploy and manage their models.
TensorFlow Serving: TensorFlow Serving is a high-performance serving system specifically designed for TensorFlow models. It provides a reliable and scalable solution for deploying TensorFlow models in production environments.
TensorFlow Serving supports various deployment scenarios, including model versioning, dynamic batching, and model management. It ensures efficient serving of TensorFlow models with low latency and high throughput.
Collaboration and Knowledge Sharing
In the realm of machine learning deployment, collaboration and knowledge sharing play a crucial role in accelerating the implementation of models. By fostering collaboration between data scientists and IT/operations teams, establishing knowledge-sharing practices, leveraging shared repositories and model registries, and encouraging cross-functional training and skill development, organizations can maximize their efficiency in deploying any machine learning model. Let’s delve into these strategies in detail:
Facilitating collaboration between data scientists and IT/operations teams:
Foster collaboration between data scientists and IT/operations teams to expedite deployment. Encourage regular meetings, joint planning sessions, and cross-team collaborations for a cohesive workflow.
Establishing knowledge-sharing practices and documentation:
Promote knowledge sharing by documenting processes and best practices. Conduct regular knowledge-sharing sessions and internal presentations to exchange ideas and foster continuous learning.

Leveraging shared repositories and model registries:
Utilize shared repositories and model registries to centralize storage and versioning of models and code. Improve collaboration and maintain consistency across deployments.
Encouraging cross-functional training and skill development:
Promote cross-functional training to enhance versatility and agility. Encourage data scientists and IT/operations teams to acquire knowledge in each other’s areas and contribute beyond their core expertise. Offer training programs, workshops, and mentorship initiatives.
Risks and Challenges in Machine Learning Deployment
While machine learning deployment offers significant benefits, it also presents risks and challenges that need to be addressed:

Disadvantages of real-time synchronous inferencing
Real-time synchronous inferencing involves making predictions in real time, where computational power and latency requirements are critical factors. The challenges associated with real-time inferencing include:
Computational power: Real-time predictions often require significant computational resources, especially for complex models or large datasets. Ensuring sufficient computing power can be a challenge.
Latency requirements: Real-time inferencing demands low latency to provide timely predictions. Achieving low latency can be challenging, especially when dealing with large-scale data or complex models.
Risks and challenges of offline batch inferencing
Offline batch inferencing involves generating predictions in a batch or offline manner. While it offers advantages in certain scenarios, there are risks and challenges to consider, including:
High cardinality key spaces: In scenarios with high cardinality, such as predicting outcomes for a large number of unique entities, managing and storing the corresponding predictions can be impractical.
Frequent updates: If the underlying data or models require frequent updates, managing and coordinating the batch inferencing process can become challenging, especially when dealing with large datasets.

Challenges in monitoring machine learning systems
Monitoring machine learning systems is crucial to ensure their performance, reliability, and accuracy. The challenges in monitoring include:
Ensuring uptime: Monitoring the availability and responsiveness of deployed models to minimize downtime and ensure uninterrupted service.
Latency monitoring: Measuring and monitoring the latency of predictions to ensure they meet the defined service-level objectives.
Detecting failures: Establishing mechanisms to detect and handle failures in the deployment infrastructure or the model itself, such as infrastructure failures, model crashes, or data quality issues.
Monitoring model drift: Continuously monitoring the performance of deployed models to detect and address model drift, where the model’s predictive power deteriorates over time due to changes in data distributions or other factors.
Importance of Choosing the Right Machine Learning Deployment Tool
When selecting a machine learning deployment tool, several considerations should be taken into account. These include:

Analyzing features and capabilities: It’s important to thoroughly evaluate the features and capabilities offered by each tool. Look for functionalities such as model versioning, scalability, monitoring, and integration with popular ML frameworks. Consider how well the tool aligns with your specific requirements and the complexity of your deployment needs.
Considering project and deployment requirements: Take into account the specific requirements of your ML project and its deployment environment. Consider factors like the scale of deployment, latency requirements, infrastructure compatibility, and the need for customization or automation. Choose a tool that can seamlessly integrate with your existing systems and provide the necessary support for your use case.
Emphasizing the importance of staying up-to-date: The field of machine learning is constantly evolving, with new tools and technologies emerging regularly. It is essential to stay updated with the latest developments in the ML landscape to ensure you are leveraging the most efficient and effective deployment tools available. This includes keeping an eye on advancements in the top 9 tools mentioned and exploring new tools that may better suit your evolving needs.
Conclusion
In conclusion, efficient machine learning deployment is crucial for integrating ML into end-user applications and driving business insights and ROI. By selecting the right deployment tools, organizations can overcome challenges, accelerate deployment, and optimize the performance of their ML models. It is essential to stay informed about the evolving landscape of tools and technologies to make informed decisions in deploying machine learning models.
By incorporating the above keyword list into the content and maintaining a high keyword density, the article provides valuable insights and guidance for accelerating machine learning deployment, highlighting key strategies and tools for efficient model implementation.
FAQs
How do you maximize model performance in machine learning?
Maximizing model performance in machine learning involves several key strategies. It starts with acquiring high-quality and diverse training data, ensuring proper preprocessing and feature engineering, selecting appropriate algorithms and hyperparameters, and utilizing techniques like cross-validation and regularization.
Regular monitoring, evaluation, and fine-tuning of the model are essential, along with considering ensemble methods and advanced architectures. Proper validation and testing on unseen data and addressing issues like overfitting or underfitting contribute to maximizing model performance.
What are the methods of model deployment in ML?
The methods of model deployment in ML include embedded deployment, web API deployment, cloud-based deployment, container deployment, offline deployment, real-time synchronous inferencing, offline batch inferencing, and stream inferencing.
Each method offers distinct advantages and is suitable for different scenarios. The choice depends on factors such as latency requirements, scalability, real-time needs, and the specific use case or application.
How do you create an efficient machine-learning model?
Creating an efficient machine-learning model involves various steps. It starts with defining clear objectives, understanding the problem domain, and acquiring high-quality and relevant training data. Proper preprocessing, feature selection, and engineering are crucial for optimizing the input data. Selecting appropriate algorithms and hyperparameters, using regularization techniques, and conducting proper cross-validation is important.
Iterative model development, fine-tuning, and performance evaluation are necessary to enhance efficiency. Continuous monitoring, feedback incorporation, and updates also contribute to an efficient machine-learning model.


